




Apache Kafka is an open-source stream-processing platform developed by the Apache Software Foundation. It was initially created by LinkedIn and later open-sourced as an Apache project in 2011. Kafka is designed to handle large amounts of streaming data and facilitate real-time data processing, making it widely used in various industries for building scalable and reliable data pipelines.
Key features of Apache Kafka:
Publish-Subscribe Model: Kafka follows a publish-subscribe messaging model. Producers publish messages to Kafka topics, and consumers subscribe to those topics to receive and process the messages.
Topics: Topics are logical channels or categories to which producers send messages. Consumers subscribe to topics to read and process messages. Topics help in organizing and categorizing the data.
Partitions: Each topic is divided into partitions, which are the basic unit of parallelism and scalability. Partitions allow Kafka to distribute data across multiple brokers and enable horizontal scaling.
Brokers: Kafka brokers are servers that manage the data. They store the incoming messages in partitions, and each partition is replicated across multiple brokers to ensure fault tolerance.
Producers: Producers are responsible for sending messages to Kafka topics. They can choose which topic to publish to and can also specify the partition within the topic.
Consumers: Consumers read messages from Kafka topics. They can subscribe to one or more topics and consume messages in real time or at their own pace.
Consumer Groups: Consumer groups allow multiple consumers to work together to read from a topic. Each message within a partition is consumed by only one consumer within the group, ensuring load balancing and parallelism.
Offsets: Each message in a partition is assigned an offset, which is a unique identifier. Consumers can track their progress by maintaining the offset of the last consumed message.
Retention and Compaction: Kafka retains messages for a configurable period of time. Older messages can be automatically deleted based on retention policies. Compaction is a process where Kafka retains only the latest message for each key in a topic.
Scalability and Fault Tolerance: Kafka is designed to be highly scalable and fault-tolerant. By distributing data across multiple brokers and using replication, Kafka ensures data availability even in the face of hardware failures.
Streaming and Processing: Kafka can be used as a stream-processing platform by integrating with tools like Apache Flink, Apache Storm, or Kafka Streams. This allows for real-time data processing, analytics, and transformations on the data stream.
Ecosystem: Kafka has a rich ecosystem of tools and libraries for various purposes, including monitoring, management, data integration, and connectors to other data systems.
Apache Kafka is widely used in scenarios such as real-time analytics, log aggregation, event sourcing, monitoring, and more, due to its ability to handle high-throughput data streams reliably and efficiently.
Consider the following scenario where we can implement Apache Kafka.
when you order food from UberEat, you will get the live Location of your delivery partner. He is moving from point A to your Home Location. Each Second App shows an update on the location of the Delivery partner. So customer getting live feed about his order. When the food is delivered to you. You will get the analytics of the entire process how much cooking time it took and how much delivery time it took as compared to expected time, etc.
To design a similar application we go with the following approach,
To get the live Location of the delivery partner have the Mobile App. In the App, we write the getLocation() function which sends an updated/current location to the Uber server every 1-3 seconds. The server inserts the data into the database like date, time, location, and order_number Then it sends that order data to the associated customer.
What's the problem?
consider you have 100-1000+ delivery parents all the partners sending their location every 1-3 seconds then within a few minutes your database goes down. Why down?Because of High Insertion operations on DB. Every DB has its own Operation limits per second. As it is getting too many insert requests exponentially from one functionality of tracking the delivering partner other operations are going into the queue and the database stops responding and goes down. In the case of Uber 100-1000 is a very small number.
Are you able to identify the problem? How to deal with those? There are many services that are looking forward to consuming the same data in real-time like calculating delivery charges, traffic analysis to predict the time of delivery, analytics, etc. To perform operations. Is our solution scalable?
No, we are getting DB throughput issues. we are implementing the Apache Kafka. Apache Kafka has a property of high throughput. So Kafka is not an alternative DB because it has low and temporary storage and you can't query data in Kafka. That's why we have to implement Kafka with the Database.
The architecture of Apache Kafka
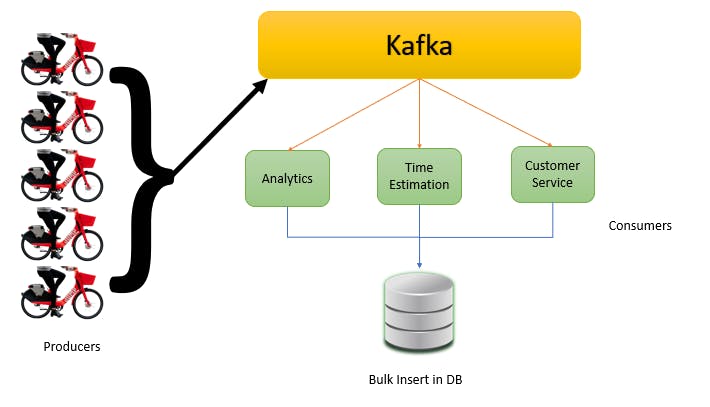
All the delivery partners who produce the data are the Producers. That data send to Kafka to all the services that want to consume the real-time data are consumed through Kafka. Also known as Consumer At the end single bulk insertion query on Database.
Let's Learn More About Kafka Architecture
Producers produce the data inside Kafka. a consumer consumes the data through the Topics. Inside Kafka many topics. The Topics are basically logically separated groups like WhatsApp or Facebook groups. with the help of topics, we are partitioning the data. In our previous scenario, we can have two topics one for a restaurant to show order status like preparing, cooking or packing and another topic for a delivery partner like your food is picked, on the way, and reach your apartment like that. Every consumer subscribes to the topics. One consumer can subscribe to one or many topics. Producer has rights to which topic produces the message or data.
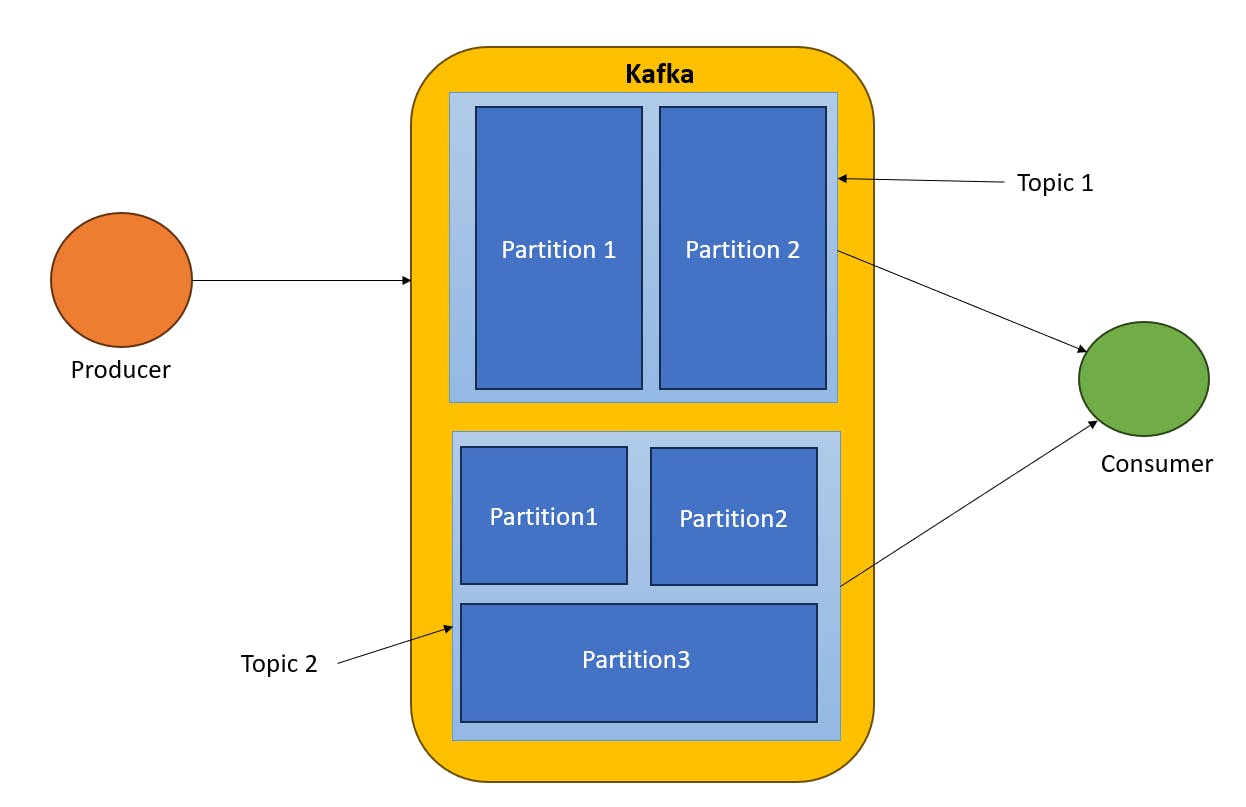
Partition parameters depend on your application like Location. As per consumer needs you divided the database into small chunks. In the case of new consumers who only want Access the Topic 2 and Partition 3. It totally depends on the Application scenario.
Auto Balancing of Partitions in Kafka
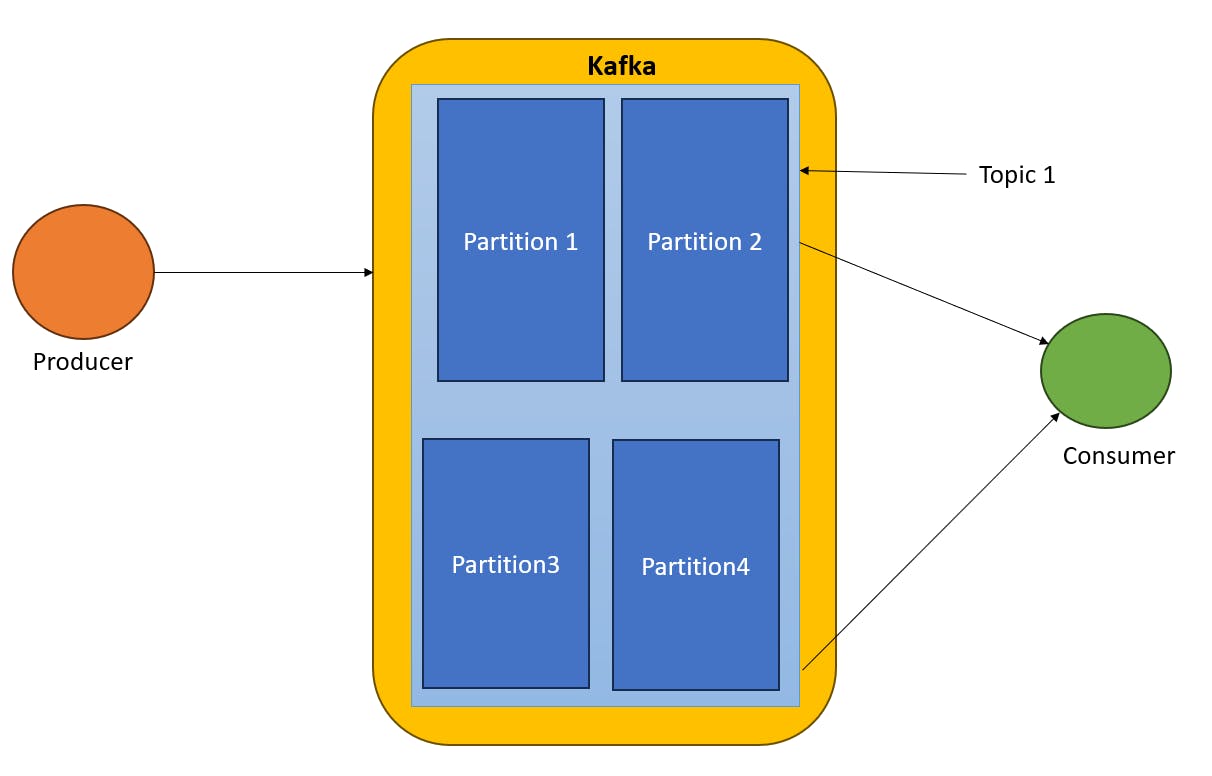
In the above scenario, all the partitions are associated with only one consumer. In the case of two consumers partitions are divided in equal numbers. In the case of three one consumer got two partitions other two got one. In the case of four consumers, every consumer got one partition. In the case of five consumers one consumer is ideal(not get any partition) others got one partition.
One consumer can consume multiple partitions but one partition can consume by one consumer.
Consumer Groups
To resolve the above issue we have consumer groups whenever we are creating a new consumer which is in the default consumer group. In auto-balancing of partition is based on the consumer group. But inside the consumer group, auto-balancing partition rules apply as it is.
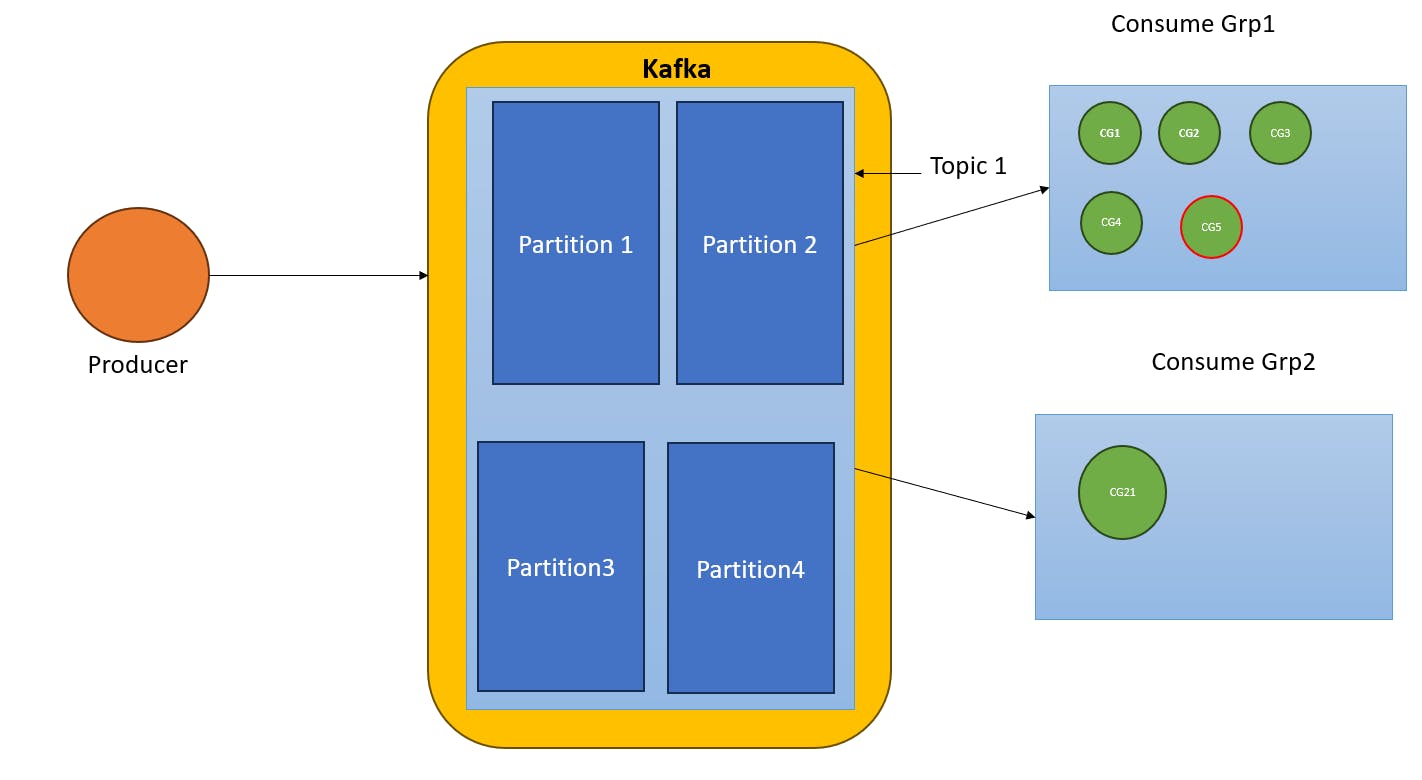
In the above example Consumer Group 1 CG, CG2, CG3, and CG4 consume one partition only CG5 does not consume any partition. In Consumer Group 2 CG21 consumes all four partitions.
Using Consumer Groups Apache Kafka represents itself as Queue and Pub/Sub both. you can implement apache kafka both ways as a queue or as a pub/sub as per your need and requirements.
What is the Apache Zookeeper?
Apache Kafka internally uses apache zookeeper to manage the Consumer Group and auto-balancing partitions. we have just start the zookeeper service that's it rest of it taken care of by Apache Kafka.
Let's Code
Requirements
Docker
NodeJs
Installation
I hope you download and install NodeJs and Docker into your system.
Install Zookeeper Docker Container
docker run -p 2181:2181 zookeeperInstall Apache Kafka Docker Container
docker run -p 9092:9092 \ -e KAFKA_ZOOKEEPER_CONNECT=<PRIVATE_IP>:2181 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<PRIVATE_IP>:9092 \ -e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \ confluentinc/cp-kafkaLet's mention the configuration in client.js file to connect the docker
Client.js
const { Kafka } = require("kafkajs"); exports.kafka = new Kafka({ clientId: "my-app", brokers: ["192.168.0.105:9092"], });
Let's Create Admin.js to setup the Apache Kafka in admin.js file
const { kafka } = require("./client");
async function init() {
const admin = kafka.admin();
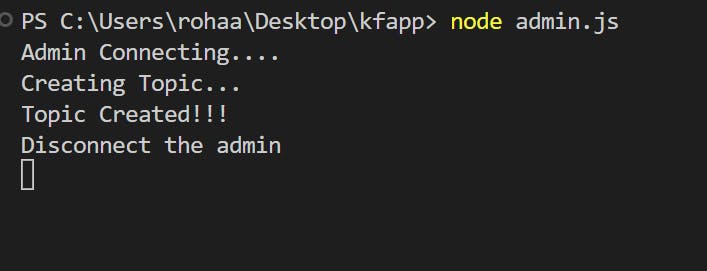
console.log("Admin Connecting....");
admin.connect("Admin Join successfully ");
console.log("Creating Topic...");
admin.createTopics({
topics: [
{
topic: "Hello-Kafka",
numPartitions: 2,
},
],
});
console.log("Topic Created!!! ");
console.log("Disconnect the admin");
await admin.disconnect();
}
init();
Let's Create the topic by running the admin.js file
Let's Create the producer and Consumer
producer.js
const { kafka } = require("./client");
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
async function init() {
const producer = kafka.producer();
console.log("Connecting Producer");
await producer.connect();
console.log("Producer Connected Successfully");
rl.setPrompt("> ");
rl.prompt();
rl.on("line", async function (line) {
const [deliveryPartnerName, location] = line.split(" ");
await producer.send({
topic: "Hello-Kafka",
messages: [
{
partition: location.toLowerCase() === "north" ? 0 : 1,
key: "location-update",
value: JSON.stringify({ name: deliveryPartnerName, location }),
},
],
});
}).on("close", async () => {
await producer.disconnect();
});
}
init();
consumer.js
const { kafka } = require("./client");
const group = process.argv[2];
async function init() {
const consumer = kafka.consumer({ groupId: group });
await consumer.connect();
await consumer.subscribe({ topics: ["Hello-Kafka"], fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message, heartbeat, pause }) => {
console.log(
`${group}: [${topic}]: PART:${partition}:`,
message.value.toString()
);
},
});
}
init();
When you run the producer it took the input from user like deliver-partner-name and direction
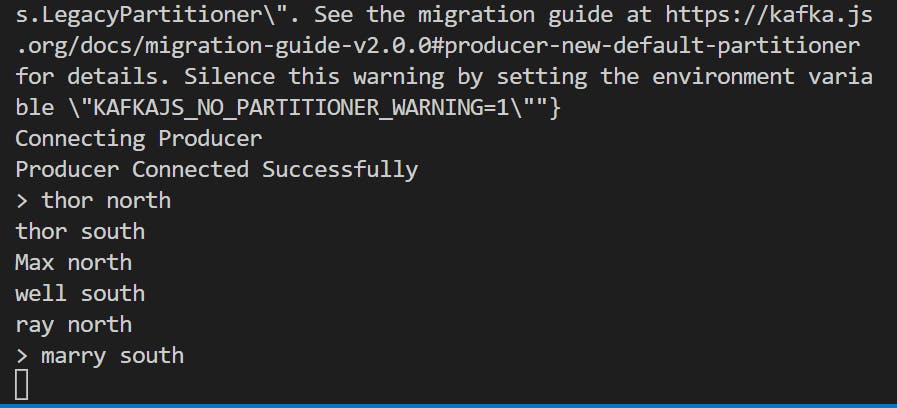
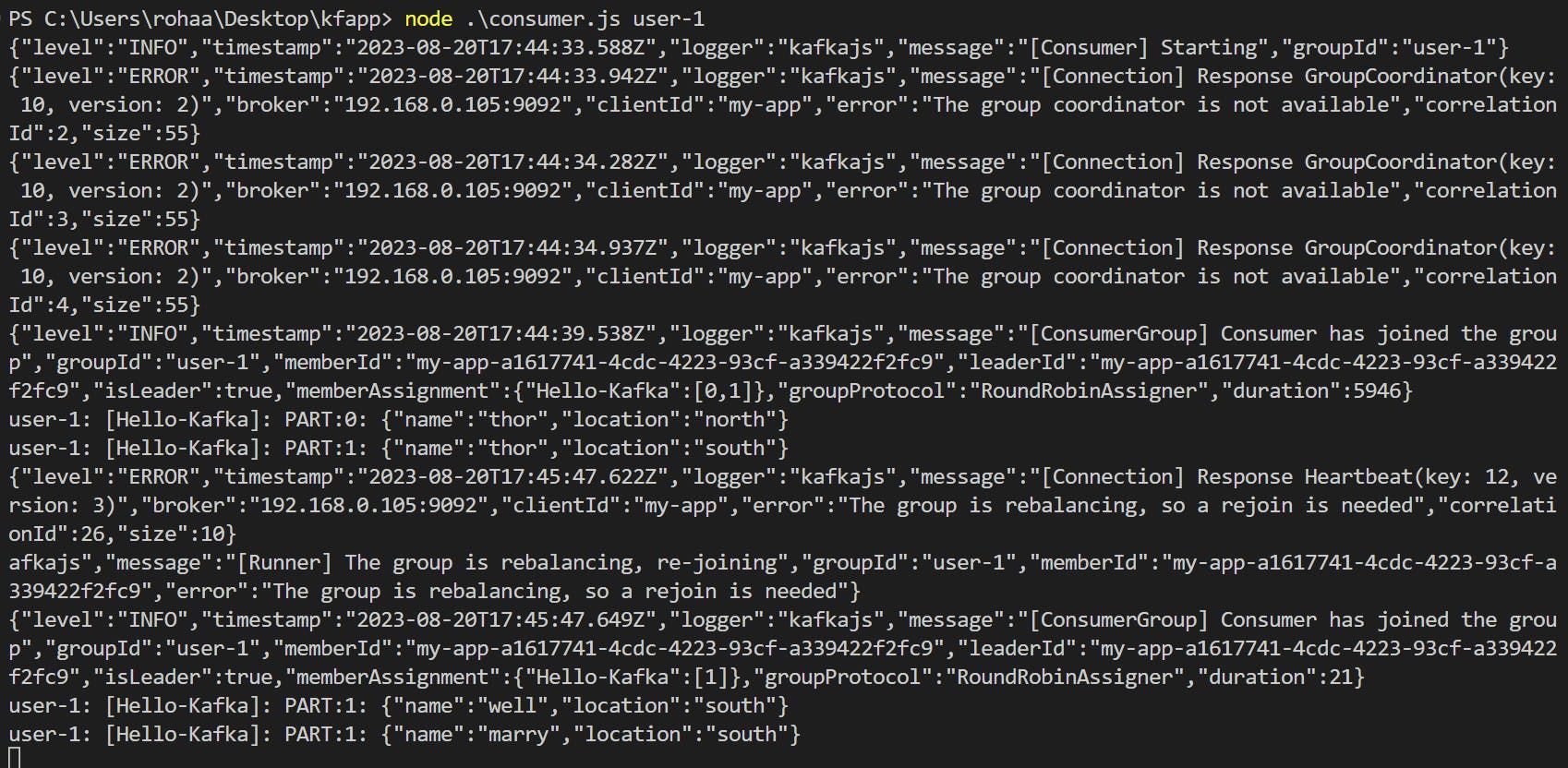
To run the consumer we have to pass the consumer group name
node consumer.js user1
For this, I created two consumer groups in user-1 two consumers and grp2 has one consumer. To verify whether our concepts work or not!!!

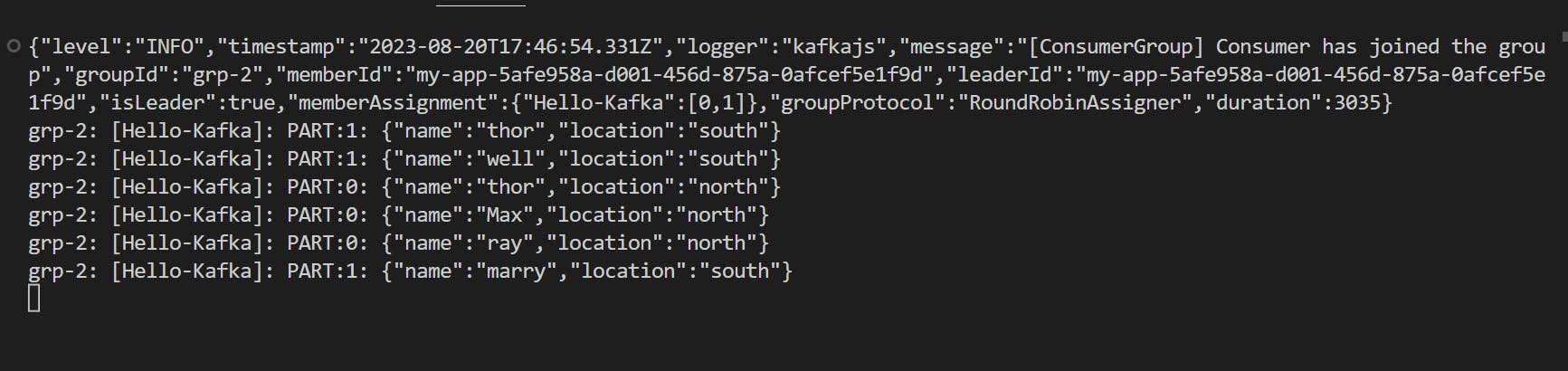
Like this, you can play with it!!! explore more about it.
References
I hope you like this crash course feel free to Like share and subscribe to my NewsLetters which are absolutely free for everyone.
Thank you!!! You are Awesome!!!!