


Unlocking the Power of Kubernetes
Exploring Core Concepts for Seamless Container Orchestration


Before starting the agenda let's understand the three major advantages of Kubernetes
High Availability or Zero downtime
Scalability with High Performance
Disaster Recovery - backup and restore
These all are achieved just by implementing Kubernetes. Let's See the architecture.
Kubernetes Architecture

Kubernetes cluster made with at least one Master Node and n-number of worker nodes. In each worker node Kubelet process running. This process helps to communicate and execute tasks. Each worker node has containers of different applications deployed on it.
On the Master node, several Kubernetes processes are running that help to manage the cluster properly.
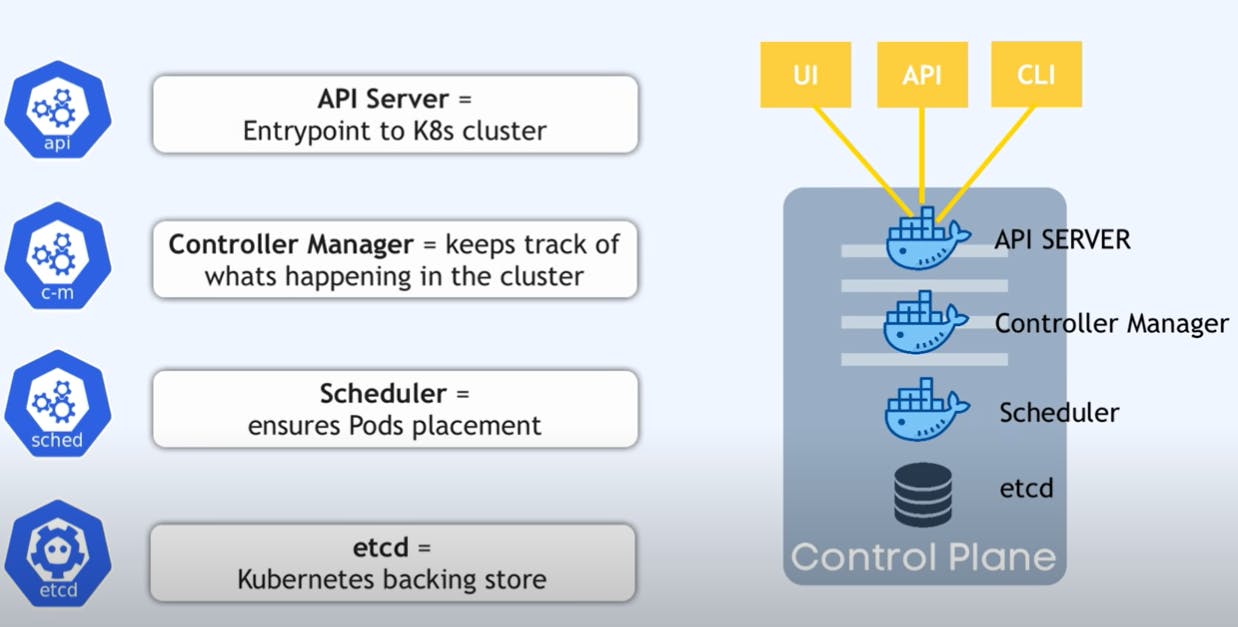
API Server: Entry point of K8s cluster. if you are using the K8s dashboard or running any scripts or CLI commands all are talking to API Server.
Controller Manager: It keeps track of what's happening in the cluster. if any repair work requires or if the container died or restarted etc.
Scheduler: It ensures Pods placement based on workload and available server resources on each node. where new Pod should be scheduled/create.
etcd: It holds the anytime current state of the Kubernetes cluster. It has all configuration data inside, and the status data of each node and each container inside of that node. It helps to recover the entire cluster from etcd snapshots.
Kubernetes Components
Node
It is a physical server or a virtual machine.
Pod
The pod is the smallest unit in Kubernetes. It is an abstraction over the container. The pod is usually made to run only one application inside it. Each Pod has its own IP address. Using virtual networks and IP address pods are communicating with each other. It is Private IP. Pods are ephemeral which means they can die very easily. If the pod dies then a new pod is created and assigned a new IP address to it.
Service
Service is a static IP address that attaches permanently to each pod. The lifecycle of the pod and service are not connected. if the pod dies still its service and IP address stays. You don't have to change endpoints every time. Service also works as a load balancer whichever pod is less busy it forwards requests to that pod.
There are two types of service
External Service:
When you want to expose your application to the rest of the world you are using an external service.
Internal Service
It is the default service. Where database-like service you don't want access over the internet or don't want to expose to it rest of the world. for that internal services are used.
Ingress
It is used to route traffic to different services. Instead of directly requesting service, It goes via Ingress. It forwarded requests to the appropriate service.
Config Map
It does the external configuration of your application like environment variables. If you do any changes in services or the database URL changed, in that case, you have to rebuild the fracture from the start instead of that you can use configMap to store the configuration that can be accessible to the pod. Pod gets the data configMap contains. if you want to do any changes in service or in environment variables you have to update those in ConfigMap.
Secret
Putting usernames, passwords or access keys like credentials in plain text format is very risky and insecure because this Kubernetes has a secret component. It is similar to ConfigMap. Used to store credentials data like username, password, and access keys in base64 encoded format. Still, it is not that secure to do encryption you can use third-party services or tools by deploying them on Kubernetes. It is also connected to the pod to access the data similar to ConfigMap.
Volumes
Volumes are physical storages that attach to the pod. It can be storage of Local machines or remote storage outside the K8s cluster like cloud storage. Kubernetes doesn't manage data persistence. As DevOps Engineer you are responsible for data persistence.
Deployment
Deployment is a Blueprint of the Pod. In that, you mention how many replicas of the pod you want. It allows scaling the pod.
Statefulset
It is used for stateful Apps or Databases. if we have clones or replicas of databases they need to access the same shared data storage. where you need a mechanism, that manages which pods are writing to the storage and which pods are reading data from the storage. To avoid inconsistency, this feature is provided by Statefulset. MySQL and MongoDB-like databases should be created using Statefulset. The rest of the functionality is similar to Deployment. You can scale up and down the pods as per requirement. It also makes sure that reading and writing are synced. So no database inconsistency is offered.
Note: Working with Database hosting in Satefulset is very tedious. Also, it is very common practice is that DataBase is often hosted outside of the K8s cluster. Used only for stateless applications using Deployments to maintain and scale the application.
Kubernetes Configuration
All the Kubernetes configuration goes through the master node with the process called API Server. Kubernetes clients UI dashboard, API or script or command line through kubectl - K8s CLI. They all talk to the API server and send the configuration requests to it. Which is the main and only entry point to the cluster. They request either in YAML or JSON format. If we mention in the YAML file two replicas of my-app in the request. If one of the pods died then Controller Manager sees the desired state as mentioned in the YAML file is matching the actual state or not, then takes appropriate action on it. This means automatically restarting the 2nd replica of that pod.
Writing Kubernetes Configuration files Using YAML
Every configuration file has four parts
Declaration: Here we mention, what we are creating like
DeploymentorServiceMetadata: Here we have information about the component like its name.
Specification: Here we mention, all kinds of configurations we have to apply to that component like replicas, ports, selector, template, and many more. Attributes of specification depend on the kind of declaration. Deployment and Service have their own attributes which apply at Deployment or Service.
Status: This is automatically generated and added by Kubernetes. So Kubernetes compare what is desired state and the actual state, To edit the status of the component. if the desired state not matching the actual state then Kubernetes knows there is something to be fixed. It's going to fix it. This is the basis of the self-healing feature of Kubernetes provides. Kubernetes continuously updates the status.
Note: etcd holds at any time the current status of any Kubernetes component and from here status information comes.
In next article we will do hands on Kubernetes and deploy our hello-world app in kubernetes cluster. Stay Tune...